실제 서비스 사례로 보는 아키텍처 선택
— 왜 어떤 팀은 쿠버네티스를 쓰고, 어떤 팀은 안 썼을까
앞선 글에서는
쿠버네티스 · 도커 컴포즈 · 서버리스를 이론적으로 비교했다.
이번에는 한 단계 더 들어가서,
실제 서비스 상황을 가정한 사례 중심으로 어떤 선택이 나왔는지를 살펴본다.
중요한 건 “정답”이 아니라,
어떤 조건에서 어떤 판단이 나왔는지다.
실무에서 아키텍처를 결정할 때 가장 도움이 되는 부분이기도 하다.
사례 1. 초기 스타트업의 MVP 서비스
상황 요약
- 사용자 수 적음
- 기능 변경 잦음
- 개발자 2~3명
- 운영 전담 인력 없음
이런 상황에서 가장 중요한 건
빠른 개발과 낮은 운영 부담이다.
선택: 서버리스 중심 구조
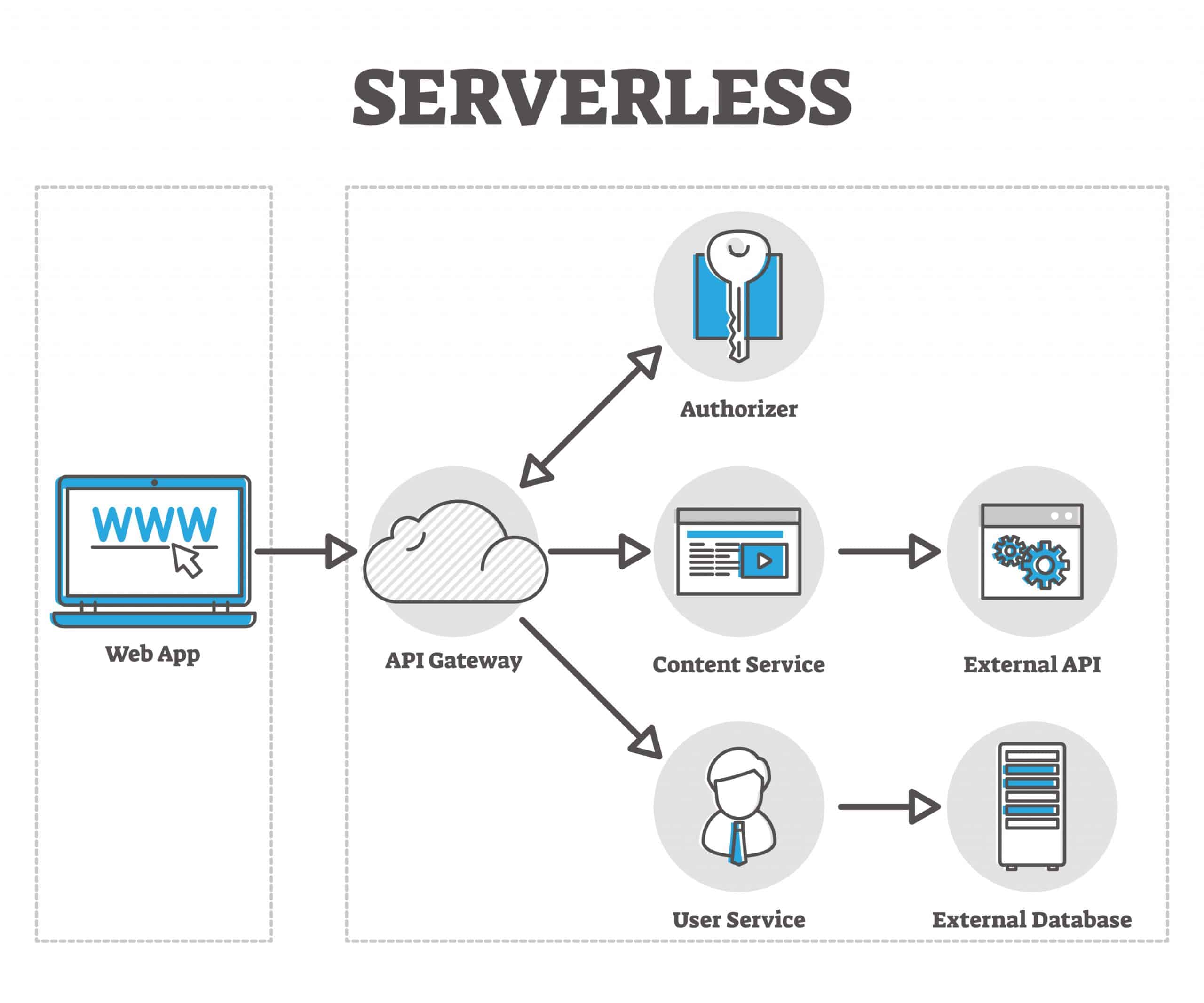

이 경우 보통 다음 선택이 나온다.
- API: 서버리스 함수
- 인증/스토리지: 관리형 서비스
- 배포: 자동화된 CI
왜 쿠버네티스를 안 썼을까
- 클러스터 운영 자체가 부담
- 장애 대응 여력 부족
- 얻는 이점보다 학습/관리 비용이 큼
이 단계에서는
“운영을 잘하는 것”보다
“운영을 안 하는 것”이 더 중요하다.
사례 2. 내부 백오피스 + 배치 중심 서비스
상황 요약
- 외부 트래픽 적음
- 내부 사용자 위주
- 주기적인 배치 작업 많음
- 단일 서버로 시작
선택: 도커 컴포즈
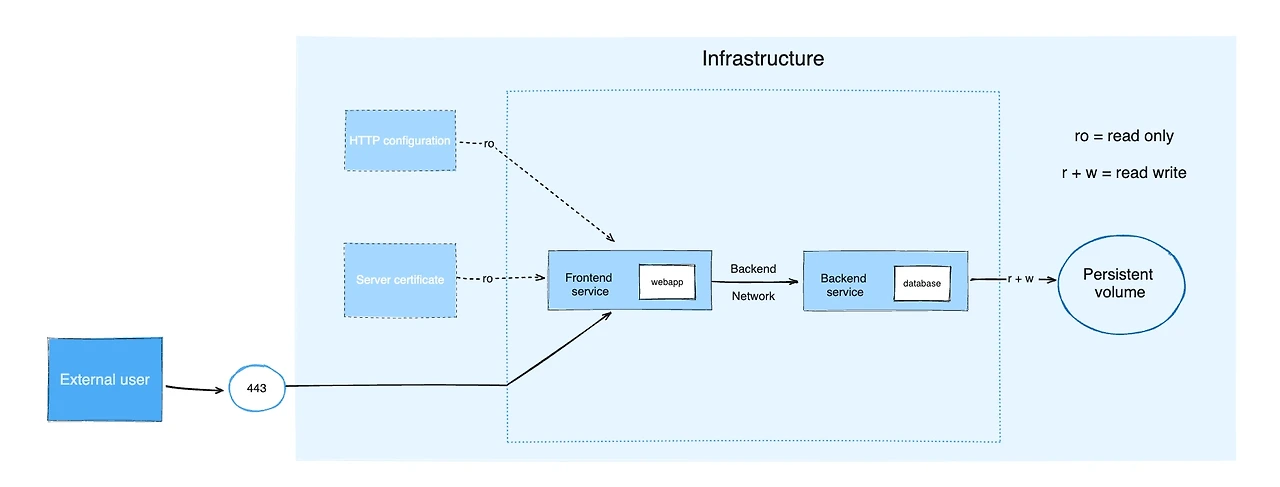

이 경우에는
도커 컴포즈가 가장 현실적인 선택이 된다.
- 서비스 구성 단순
- 서버 1~2대로 충분
- 배포 빈도 낮음
쿠버네티스를 쓰지 않은 이유
- 고가용성 요구 낮음
- 서버 장애 시 영향 범위 작음
- 운영 단순성이 더 중요
실제로 이런 서비스는
3~4년 이상 도커 컴포즈로 문제없이 운영되는 경우도 많다.
사례 3. 트래픽이 빠르게 늘어난 웹 서비스
상황 요약
- 외부 사용자 트래픽 증가
- 배포 빈도 높음
- 장애 허용 범위 낮음
- 서버 수 증가 추세
이 단계부터는
기존 방식의 한계가 분명해진다.
선택: 쿠버네티스 도입

이런 요구가 등장한다.
- 무중단 배포
- 자동 복구
- 수평 확장
- 배포 표준화
쿠버네티스가 선택된 이유
- 서버 단위 관리의 한계
- 장애 시 수동 대응 부담
- 배포 안정성 요구 증가
이 시점의 쿠버네티스는
“미래 대비”가 아니라
이미 발생한 문제를 해결하기 위한 선택에 가깝다.
사례 4. 이미 운영 중인 서비스의 점진적 전환
상황 요약
- 기존 VM/서버 기반 운영
- 서비스 중단 리스크 큼
- 한 번에 전환 불가
선택: 단계적 혼합 구조


보통 이런 흐름을 따른다.
- 신규 서비스만 쿠버네티스
- 내부 서비스부터 이전
- 핵심 서비스는 마지막에 전환
이 방식의 장점
- 리스크 분산
- 팀 학습 시간 확보
- 장애 영향 최소화
실무에서는
한 번에 전환하는 경우보다 이 패턴이 훨씬 많다.
사례 5. 쿠버네티스를 도입했다가 되돌린 경우
이런 케이스도 실제로 존재한다.
공통적인 배경
- 서비스 규모 대비 과한 구조
- 운영 인력 부족
- 클러스터 장애 대응 어려움
되돌린 이유 요약
- 장애 시 원인 파악이 더 어려워짐
- 단순한 요구에 비해 구조가 복잡
- 운영 부담 증가
이 경우에는
- 도커 컴포즈
- 관리형 PaaS
- 서버리스
같은 더 단순한 선택지로 돌아가는 판단이 나온다.
쿠버네티스를 “포기”한 게 아니라
상황에 맞는 도구로 재선택한 것에 가깝다.
사례들을 관통하는 공통 기준
여러 사례를 묶어보면,
선택 기준은 꽤 일관된다.
- 서비스 규모
- 트래픽 패턴
- 장애 허용 범위
- 운영 인력과 경험
- 변경 빈도
기술 스택보다
운영 현실이 먼저 결정하는 경우가 대부분이다.
아키텍처 선택에서 가장 위험한 신호
실무에서 가장 위험한 신호는 이것이다.
- “다들 쓰니까”
- “언젠가는 필요할 것 같아서”
- “기술적으로 멋있어 보여서”
이런 이유로 도입된 구조는
운영 단계에서 부담으로 돌아오는 경우가 많다.
정리하며
이번 글에서는
실제 서비스 상황을 가정한 사례들을 통해
아키텍처 선택이 어떻게 달라지는지 살펴봤다.
- 작은 서비스에는 단순한 구조가 유리하다
- 쿠버네티스는 문제를 겪은 뒤에 더 빛난다
- 단계적 도입은 매우 현실적인 전략이다
- 되돌리는 선택도 실패는 아니다