쿠버네티스 HPA 동작 원리 정리: 자동 확장은 어떻게 결정될까
쿠버네티스 자동 확장의 핵심, HPA는 어떻게 동작할까
앞선 글에서 requests와 limits를 다뤘다면,
이번에는 그 설정을 실제로 활용하는 기능인 HPA(Horizontal Pod Autoscaler) 를 살펴볼 차례다.
쿠버네티스를 쓰는 이유 중 하나가
“트래픽에 따라 자동으로 늘고 줄어드는 구조”일 텐데,
그 중심에 바로 HPA가 있다.
다만 HPA는 설정만 해두면 마법처럼 동작하는 기능은 아니다.
동작 원리를 이해하지 않으면,
원하지 않는 타이밍에 스케일이 되거나 아예 안 되기도 한다.
HPA란 무엇인가
HPA를 한 문장으로 정리하면 다음과 같다.
HPA는 “메트릭을 기준으로 Pod 개수를 자동 조절하는 리소스”다.
여기서 핵심은 두 가지다.
- 무엇을 기준으로 판단하는가
- Pod 개수를 어떻게 조절하는가
HPA는 Deployment, StatefulSet 같은 워크로드 위에서 동작하며,
Pod 자체를 직접 제어하지는 않는다.
HPA가 바라보는 기본 메트릭
가장 기본적인 기준은 CPU 사용률이다.
- 각 Pod의 CPU 사용량
- Pod에 설정된 requests.cpu
- 이 둘의 비율
즉, HPA는 이렇게 계산한다.
현재 CPU 사용량 / requests 값

이 구조 때문에
requests 설정이 부정확하면 HPA도 제대로 동작하지 않는다.
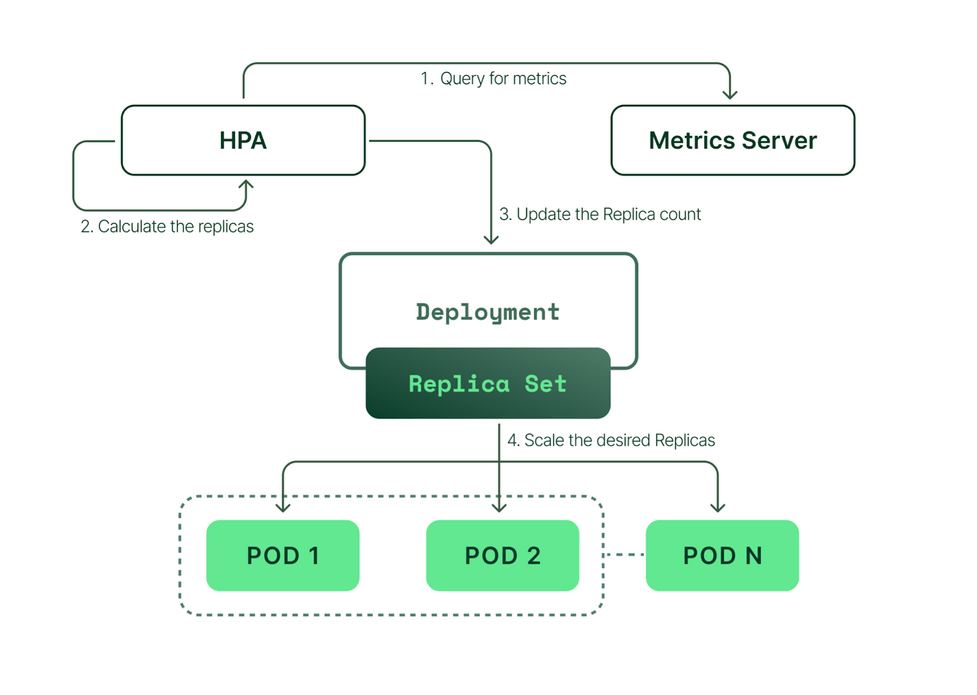
HPA 동작 흐름 정리
전체 흐름을 단순화하면 다음과 같다.
- 메트릭 서버가 Pod 리소스 사용량 수집
- HPA가 주기적으로 메트릭 조회
- 목표 값과 현재 값 비교
- Pod 개수 증가 또는 감소 결정
이 과정은 사람이 개입하지 않아도 반복된다.
다만 “언제 얼마나 늘릴지”는 설정에 따라 크게 달라진다.
HPA 설정에서 자주 쓰이는 옵션
최소 / 최대 Pod 개수
- minReplicas
- maxReplicas
이 값은 안전장치에 가깝다.
- 트래픽이 없어도 최소 개수는 유지
- 아무리 바빠도 최대 개수는 넘지 않음
실무에서는
max 값을 너무 낙관적으로 잡지 않는 것이 중요하다.
목표 CPU 사용률
averageUtilization: 60
이 설정은 다음 의미를 가진다.
- 평균 CPU 사용률이 60%를 넘으면 스케일 아웃
- 내려가면 스케일 인 고려
여기서 말하는 60%는
Node 기준이 아니라 requests 기준이다.
이 점을 놓치면
“CPU가 남아 있는데 왜 늘어나지?” 같은 혼란이 생긴다.
메모리 기준 HPA는 왜 조심해야 할까
HPA는 메모리 기준으로도 동작할 수 있다.
하지만 실무에서는 신중하게 사용된다.
이유는 명확하다.
- 메모리는 CPU처럼 자연스럽게 내려가지 않는다
- GC, 캐시 구조에 따라 변동이 크다
- 스케일 인 타이밍을 예측하기 어렵다
그래서 보통은
- CPU 기준 HPA
- 메모리는 limits로 보호
이 조합이 가장 많이 쓰인다.
실제로 써보면 겪는 문제들
운영 환경에서 자주 마주치는 상황은 다음과 같다.
- HPA가 전혀 동작하지 않는다
→ 메트릭 서버 미설치 - 갑자기 Pod가 많이 늘어난다
→ requests 값이 너무 작음 - 트래픽이 줄어도 Pod가 안 줄어든다
→ 안정화 시간, 메트릭 특성 문제
특히 첫 번째 문제는
로컬 환경이나 초기 클러스터에서 자주 발생한다.
HPA가 만능은 아니다
⚠️ HPA는 “리소스 사용량 기반 자동 확장”일 뿐이다.
다음과 같은 경우에는 한계가 있다.
- 트래픽 예측이 필요한 경우
- 요청 수 기반 스케일링이 필요한 경우
- 급격한 트래픽 스파이크
이럴 때는
- 사전 스케일링
- 외부 메트릭 기반 확장
같은 추가 전략이 필요해진다.
정리하며
이번 글에서는 쿠버네티스의 자동 확장 기능인
HPA의 동작 원리와 실무 포인트를 정리했다.
- HPA는 메트릭 기반으로 Pod 개수를 조절한다
- requests 설정이 전제 조건이다
- CPU 기준이 가장 안정적이다
- 모든 상황을 해결해주지는 않는다
다음 글에서는
자동 확장과 함께 자주 언급되는 주제인
로그와 모니터링,
즉 쿠버네티스 환경에서 관측 가능성을 어떻게 확보하는지 살펴볼 예정이다.